最全视频数据集分享系列一 | 动作识别数据集
在当今数字化时代,人工智能已渗透到各个领域,成为推动技术革新和社会发展的关键力量。从早期的基于规则的简单算法,逐步演变为如今以深度学习为代表的复杂智能系统,人工智能的每一次重大突破都与数据的指数级增长和处理能力的飞跃紧密相连。而视频数据,作为一种信息密集且生动直观的数据源,在这一演进过程中扮演着至关重要的角色。随着视频数据的大量产生和广泛应用,视频理解技术变得越来越重要。它可以实现视频内容的自动分类、标注和检索,提高视频处理的效率和准确性,为各种应用提供有力支持,如视频监控、智能交通、影视制作、在线教育等领域。
视频数据集为大模型提供了丰富的时空信息,使模型能够学习物体运动、场景变化和事件发展等动态特征。高质量的视频数据集涵盖了多样化的场景、动作和情境,这有助于提高模型的泛化能力,使其在面对真实世界的复杂性时更加稳健。在文生视频等新兴任务中,全面而多样的视频数据集更是不可或缺,它们为模型提供了从文本到视觉序列的映射知识。
动作识别数据集:解锁视频理解和生成的钥匙
动作识别(Action Recognition) 旨在对视频中的人类或物体动作进行精准分类和深入理解。它通过挖掘视频序列所蕴含的丰富时空信息,自动提取关键动作特征,并将这些特征与预设的动作类别进行高效匹配,从而准确判定视频中正在发生的动作类型。
动作识别数据集作为视频数据集的一个重要子集,专注于人类动作的识别与分类任务。它包含了丰富多样的人类动作视频样本,涵盖了从简单的肢体动作(如行走、跑步、挥手等)到复杂的行为活动(如体育比赛中的各种动作、工业生产中的操作流程、社交互动中的行为表现等),并且针对每个动作视频都进行了精确的动作类别标注,有些数据集还会进一步提供动作的起始和结束时间、动作的详细描述以及执行动作的主体和对象等详细信息。
在生成式人工智能领域,动作识别数据集发挥着至关重要的作用:
-
为动作生成提供了坚实的基础和丰富的素材。生成式人工智能模型旨在创造出全新的、逼真的内容,而动作识别数据集中的海量动作样本能够让模型学习到不同动作的细节特征和变化规律。例如,在虚拟现实(VR)和增强现实(AR)应用中,为了创造出栩栩如生的虚拟角色动作,模型需要借助动作识别数据集来学习人类动作的自然流畅性和协调性,从而生成符合物理规律和人类行为习惯的动作序列,极大地增强了虚拟场景的真实感和沉浸感。
-
有助于实现多模态融合。在实际应用中,单一模态的数据往往难以满足复杂的任务需求,而将动作识别数据与其他模态(如图像、音频、文本等)相结合,可以使模型获得更全面、深入的信息理解和表达能力。例如,在视频内容生成任务中,通过将文本描述与动作识别数据相结合,模型能够根据给定的文本情节生成相应的视频动作,实现从文字到动态影像的智能转换,为影视创作、广告制作等领域提供了全新的创意工具和高效的生产方式。
-
有效增强模型的泛化能力。由于数据集中涵盖了各种不同场景、人物、动作类型的样本,模型在学习过程中能够接触到广泛的动作变化情况,从而在面对新的、未见过的动作生成任务时,能够凭借所学的知识和模式进行合理的推断和创造,减少对特定数据的过度依赖,提高模型在不同应用场景下的适应性和可靠性。
动作识别数据集的存在为生成式人工智能在多个领域的应用创新开辟了广阔的道路。在影视制作中,导演和特效师可以利用基于动作识别数据集训练的模型生成各种奇幻、惊险的动作特效,丰富影片的视觉效果;在游戏开发领域,能够为游戏角色赋予更加多样化、个性化且自然流畅的动作行为,提升游戏的趣味性和玩家的沉浸体验;在智能机器人领域,机器人可以通过学习动作识别数据集中的人类动作模式,更好地理解人类的指令和意图,实现更加精准、自然的人机交互,从而拓展机器人在家庭服务、医疗护理、工业协作等场景中的应用范围。
本期将介绍一些经典的动作识别数据集。
UCF-101
- 发布方:佛罗里达中央大学
- 下载地址:https://www.crcv.ucf.edu/research/data-sets/ucf101/
- 发布时间:2012
- 简介:UCF-101 数据集是一个著名的视频动作识别数据集,由13320个视频片段组成,涵盖了101种不同的人类动作类别。UCF101的独特之处在于其多样化的动作类别,涵盖了广泛的日常活动和体育运动。这101个类别可分为5类(身体运动、人与人互动、人与物互动、乐器演奏和运动)。 每个视频展示了一个清晰的动作,从体操到帆船运动,从击剑到举重等。
研究团队从YouTube等视频平台下载了相关视频,确保视频的多样性和代表性。选择过程中应用了一系列筛选标准,如限制视频时长、确保视频清晰度和动作类别的准确标记。在视频片段的标注阶段,研究者通过人工标注和验证,保证了每个视频片段与其动作标签的准确对应。

UCF-101 数据集示例
Kinetics
- 发布方:Deepmind
- 下载地址:https://www.deepmind.com/open-source/kinetics
- 论文地址:https://arxiv.org/abs/1705.06950
- 发布时间:2017
- 简介:Kinetics 是一个广泛应用的大规模视频数据集,旨在促进视频动作识别和深度学习模型的研究。这个数据集包含数十万个视频片段,涵盖了400(Kinetics-400)、600(Kinetics-600)、以及700(Kinetics-700)种不同的人类动作类别,具体数量取决于数据集的版本。Kinetics的独特之处在于其大规模和高多样性的动作类别,涉及各种复杂的人类活动:每个视频展示一个特定的动作,从日常活动到复杂的体育项目,从社交互动到游戏玩法等。
研究团队从YouTube等开放平台收集了大量视频,通过自动化和人工审核步骤,确保覆盖多样化和有代表性的动作类别,并最终精炼出特定数量的视觉任务(如400、600、或700)。在选择视频时,他们使用了一系列严格的筛选标准,确保视频质量、动作清晰性及标签准确性。每个视频片段都有相应的动作标签,这些标签通过半自动的方法进行初步分配,并经过人工验证以保证标注的高准确性和一致性。
Kinetics 数据集因其规模庞大且动作类别详细,被广泛用于训练和评估各种视频理解模型,特别是在动作识别任务中。尽管数据集在标注准确性上付出了很大努力,但其来源的多样性和开放性仍可能引入一些标签噪声。然而,这种大规模的数据集为研究人员提供了充分的资源来开发和验证先进的视频分析算法。

Kinetics 数据集示例
Charades
- 发布方:The Allen Institute for AI, Carnegie Mellon University
- 下载地址: https://prior.allenai.org/projects/charades
- 论文地址:https://arxiv.org/abs/1604.01753
- 发布时间:2016
- 简介:Charades数据集由 9,848 个带注释的视频组成,平均长度为 30 秒,显示来自三大洲的 267 人的活动,总时长约为80小时。每个视频都由多个自由文本描述、动作标签、动作间隔和交互对象的类别进行注释。Charades 总共提供了 27,847 个视频描述、157 个动作类别的 66,500 个时间定位间隔和 46 个对象类别的 41,104 个标签。
研究团队设计了一种新颖的方法来收集和标注该数据集。他们首先生成了一长串可能发生的活动清单,并由亚马逊Mechanical Turk的用户来重现这些活动。参与者根据给定的描述在家中录制视频。这些描述不是简单的独立活动,而是复杂且多步骤的情景描述。例如,一段视频可能呈现一个人从起床、穿衣到吃早餐的一系列连续动作。

Charades 数据集和 YouTube 上的视频动作比较
ActivityNet
- 下载地址:http://activity-net.org/index.html
- 论文地址:https://ieeexplore.ieee.org/document/7298698
- 发布时间:2015
- 简介:ActivityNet是一个大型视频数据集,数据量庞大,涵盖的活动种类繁多。包含多达20,000个视频,总时长超过849小时,涵盖200种不同的人类活动类别。ActivityNet的特色在于其广泛的活动多样性,这些活动涉及日常生活、运动、娱乐等各种场景。数据集的 1.3 版总共包含 19994 个未修剪的视频,并以 2:1:1 的比例分为三个不相交的子集,训练、验证和测试。平均而言,每个活动类别有 137 个未修剪的视频。每个视频平均有 1.41 个带有时间边界注释的活动。测试视频的基本事实注释不公开。
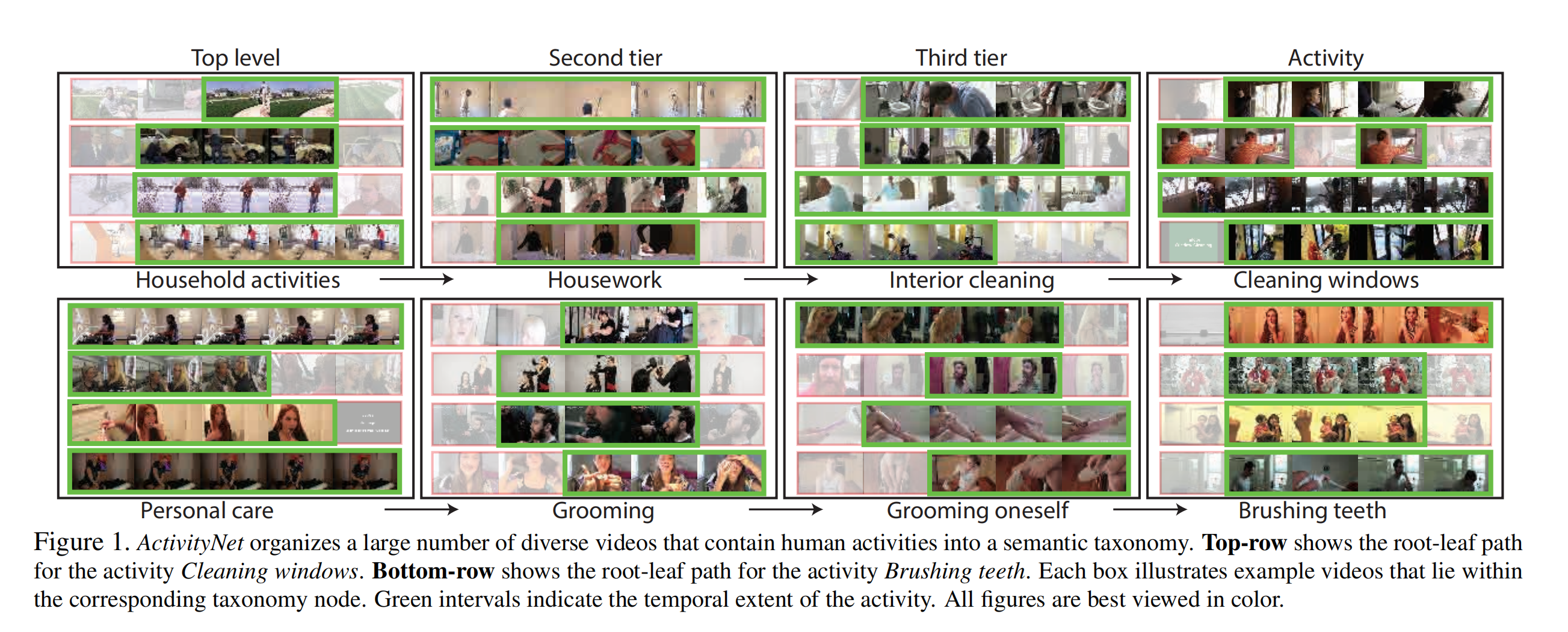
ActivityNet 数据集示例
MMAct
- 下载地址:https://mmact19.github.io/2019/
- 论文地址:https://ieeexplore.ieee.org/document/9009579
- 发布时间:2019
- 简介:MMAct是一个开创性的大规模多人交互动作数据集,旨在推动视频理解和多模态学习的研究。这个数据集包含多种传感器数据和视频片段,涵盖了各种不同的人际交互和独立动作任务。MMAct的独特之处在于其专注于多模态交互内容:每个数据片段展示了多个人完成特定任务时的动作和互动,从日常生活活动到复杂的协调运动等。
研究团队通过分析常见人际互动场景获取了大量活动列表,并通过筛选主要类别的“交互任务”,重点关注涉及多种感官和物理世界互动的活动,最终精炼出具体的视觉任务。随后,他们设计了一系列实验,捕获包括视频、深度数据、惯性测量单位(IMUs)等在内的多模态数据,确保数据的多样性和质量。
在数据片段和注释文本配对阶段,研究者使用了一系列传感器数据作为描述文本,精确标记每个动作的开始和结束时间。这一过程采用多模态的融合技术,结合视频、IMU数据和其他传感器信息,以提供全面的动作表示。尽管这种方法可能引入复杂的配对和处理需求,但它能够真实反映多模态传感数据与实际动作的关系。

MMAct 数据集示例
THUMOS
- 下载地址:http://www.thumos.info/home.html
- 发布时间:2013-2015
- 简介:THUMOS Challenge是一个面向学术界和工业界的年度竞赛,旨在推动视频分析领域,特别是动作识别和动作检测技术的发展。这项挑战利用THUMOS数据集进行评估,THUMOS数据集主要包括以下几个版本:
- THUMOS’13:这是该系列的第一个版本,作为挑战赛的一部分推出,主要用于动作分类(Action Classification)任务。数据集包含了大量的体育动作类别,利用YouTube视频进行构建
- THUMOS’14:在此版本中,不仅包含了动作分类任务,还引入了动作检测(Action Detection)任务。数据集包括验证集和测试集,标注了每个视频中动作发生的时段。THUMOS’14包括101种动作类别,并为检测任务提供了精确的时间边界。
- THUMOS’15:这一版基本上沿用了THUMOS’14 的数据和任务设置,但视频的标注质量和挑战赛的评估方法有所改进,以进一步推动动作检测领域的研究。THUMOS‘15 包含超过 430 小时的视频数据和 4500 万帧,目前已经开放。具有以下组件:
训练集:来自 101 个动作类别的超过 13,000 个临时剪辑的视频。
验证集:超过 2100 个暂时未修剪的视频,带有动作的时间注释。
背景设置:大约 3000 个相关视频,保证不包含 101 个动作的任何实例。
测试集:超过 5600 个暂时未修剪的视频,其中隐藏了真实情况。
对于从事视频动作识别和检测研究的人员来说,THUMOS数据集提供了一种标准化的测试平台,促进了算法创新和改进。由于其标注精确且含有多样性的动作类别,它常用于学术研究和算法开发中的基准测试。
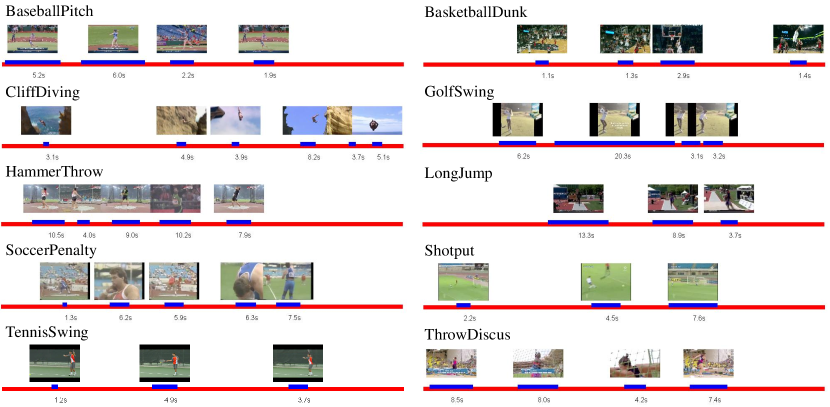
THUMOS'15 数据集验证集的八个视频样本的时间注释
Multi-THUMOS
- 下载地址:https://ai.stanford.edu/~syyeung/everymoment.html
- 论文地址:https://arxiv.org/abs/1507.05738
- 发布时间:2016
- 简介:Multi-THUMOS是对原始THUMOS数据集的扩展和增强版,专门用于多标签动作检测任务。它通过在传统的单标签动作检测任务基础上,增加了多标签的标注,使得同一时间段内可以有多个动作标签。这种增强对于现实世界中的视频分析更具挑战性,因为在许多实际场景中,不同的动作可能会同时发生。相比单标签的数据集,这更接近于现实情况,提高了模型对复杂场景的适应能力。Multi-THUMOS为视频理解领域带来了新的挑战,促使研究人员向更复杂、更具鲁棒性的多标签检测模型迈进。这不仅推动了技术的发展,也为各种实际应用提供了更坚实的基础。
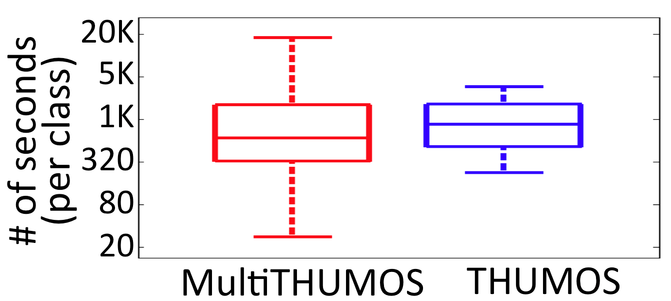
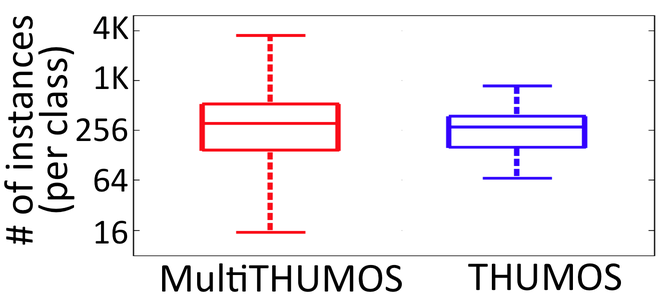
AVA Actions
- 发布方:谷歌、UC Berkeley
- 下载地址:https://research.google.com/ava/
- 发布时间:2018
- 简介:AVA Actions是一个开创性的大规模视频动作数据集,旨在推动视频理解和时序动作识别的研究。这个数据集包含多个人物的动作标注,涵盖了丰富多样的日常生活活动和互动行为。AVA Actions的独特之处在于其专注于高质量的时序动作注释:每个视频片段精确标注了人物在具体帧内的动作,从简单的走路到复杂的多人互动等。
研究团队从YouTube电影中获取了大量动态场景,并通过筛选主要类别的“动作任务”,重点关注涉及人类行为和环境互动的活动,最终精炼出了具体的动作类别。随后,他们从公开可用的电影视频中提取相应片段,应用细致的注释标准,对每个动作框架进行逐帧标记。
在视频片段-动作标签配对阶段,研究者将每个动作类别与对应的视频帧精确配对,确保高精度的时间和动作标注。这一过程采用了全面的人工标注方法,结合动作分类和定量评估,以提供精确的动作识别基准。尽管这种方法需要大量的人力和时间投入,但它能够真实反映复杂自然场景中人类动作的细节。

AVA 数据集标注示例
HMDB51
- 发布方:Brown University 计算机视觉团队
- 下载地址:https://serre-lab.clps.brown.edu/resource/hmdb-a-large-human-motion-database/
- 论文地址:https://ieeexplore.ieee.org/document/6126543
- 发布时间:2011
- 简介:HMDB51数据集由来自 51 个动作类别(的 6,766 个视频片段组成,每个类别至少包含 101 个片段。最初的评估方案使用三种不同的训练/测试分组。在每个分组中,每个动作类别都有 70 个用于训练的剪辑和 30 个用于测试的剪辑。这三个分割的平均准确度用于衡量最终性能。数据量小,方便下载和使用;分辨率320*240,完整数据集大小约2GB,来自各种来源的真实视频的大量集合,包括电影和网络视频。动作主要分为五类:1)一般面部动作(微笑、大笑等);2)面部操作与对象操作(吸烟、吃、喝等);3)一般的身体动作(侧手翻、拍手、爬楼梯等);4)与对象交互动作(梳头、高尔夫、骑马等);5)人体动作(击剑、拥抱、亲吻等)。
Sports-1M
- 发布方:谷歌,斯坦福大学计算机科学系
- 下载地址:https://github.com/gtoderici/sports-1m-dataset/
- 论文地址:https://ieeexplore.ieee.org/document/6909619
- 发布时间:2014
- 简介:Sports-1M 数据集由来自 YouTube 的超过一百万个视频组成。数据集中包含超过110万个视频剪辑,总时长超过5000小时。通过分析与视频相关的文本元数据(例如标签、描述),使用 YouTube 主题 API 自动标记视频。数据集涵盖了487种不同的体育活动类型,包括足球、篮球、游泳、体操等。每个类别有 1,000 到 3,000 个视频。每个视频都被分配了一个或多个体育类别的标签,这些标签基于视频的主要内容自动生成,大约 5% 的视频带有多个类的注释。
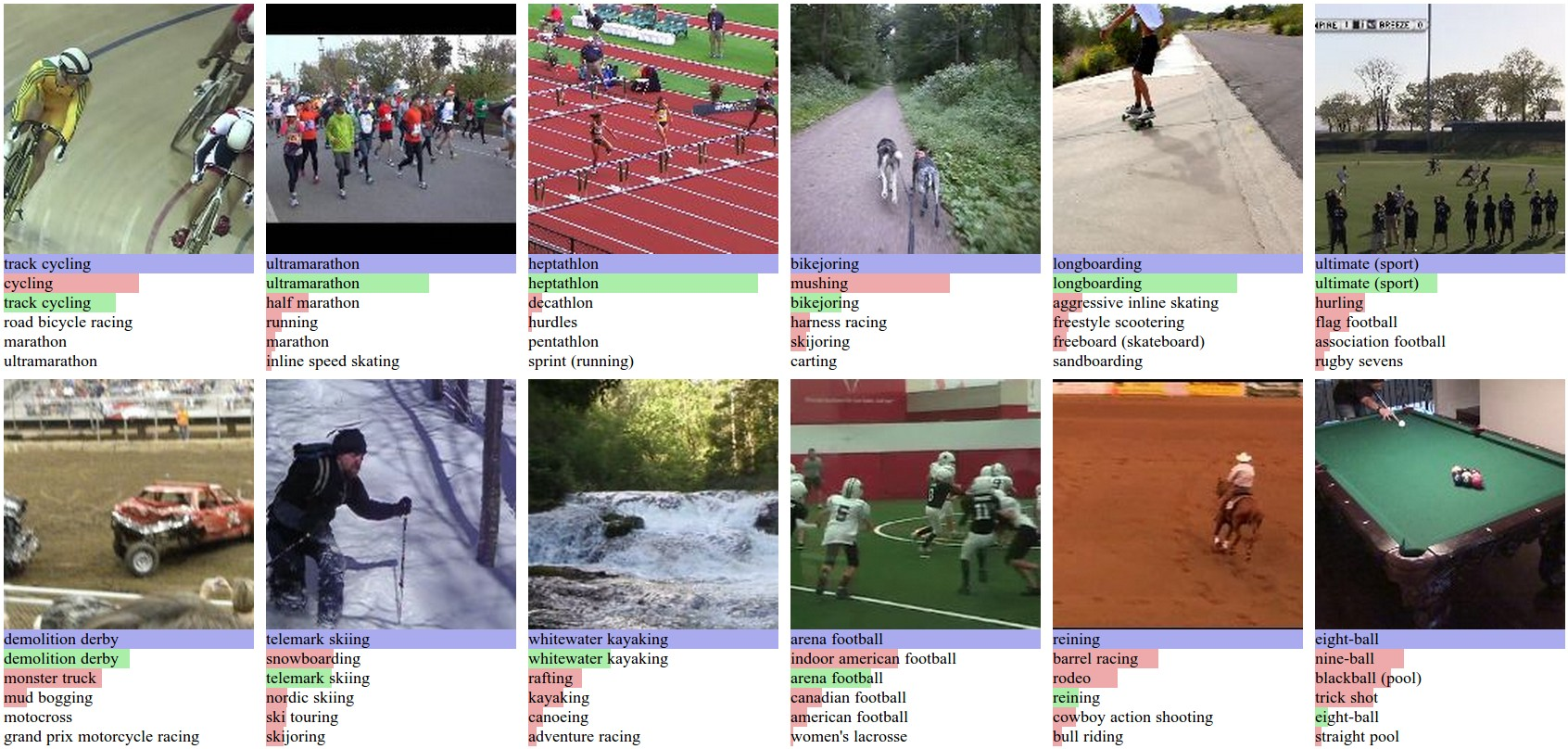
对Sports-1M 测试数据的预测
总结
动作识别视频数据集作为AI视觉领域的关键资源,为模型训练提供了丰富的素材和精准的指导,推动着动作识别技术不断突破,进而在众多领域实现广泛而深入的应用,持续拓展人工智能的边界,让机器更加智能地理解和融入人类的行为世界,为构建更加智能、便捷、安全的社会环境奠定坚实基础。
整数智能信息技术(杭州)有限责任公司,起源自浙江大学计算机创新技术研究院,致力于成为AI行业的数据合伙人。整数智能也是中国人工智能产业发展联盟、ASAM协会、浙江省人工智能产业技术联盟成员,其提供的智能数据工程平台(MolarData Platform)与数据集构建服务(ACE Service),满足了智能驾驶、AIGC等数十个人工智能应用场景对于先进的智能标注工具以及高质量数据的需求。

目前公司已合作海内外顶级科技公司与科研机构客户1000余家,拥有知识产权数十项,通过ISO9001、ISO27001等国际认证,也多次参与人工智能领域的标准与白皮书撰写,也受到《CCTV财经频道》《新锐杭商》《浙江卫视》《苏州卫视》等多家新闻媒体报道。

 浙公网安备33010902003900
浙公网安备33010902003900