最全具身智能数据集分享系列 | 全球有哪些高质量具身智能数据集
2024年白驹过隙,人工智能在模型、算力与数据层面蓬勃发展,并由虚拟交互逐渐向物理实体落地演化。随着大模型和机器人技术的发展,具身智能(Embodied AI)赋予人工智能系统物理形态以实现与环境的互动和学习。从动作编程到人类遥操作,从机械臂到灵巧手,从硅谷到中国,具身智能在软硬件层面逐步建立起发展范式。
借鉴自动驾驶汽车发展的路径,数据对于具身智能同样至关重要,数据不仅作为“燃料”驱动智能体感知与理解环境,通过多模态传感器(如视觉、听觉、触觉)帮助构建环境模型并预测变化,使智能体能够根据历史数据进行情境感知和预测性维护,从而做出更优决策。构建高质量、多样化的感知数据集是不可或缺的基础工作,这些数据集不仅为算法训练提供了丰富的素材,也成为了评估具身性能的基准参考标准。
整数智能始终致力于成为“人工智能行业的数据合伙人”。继往开来,不妨让我们来看看全球范围内有哪些高质量的具身智能数据集。
| 具身智能数据集 | 发布机构 | 发布时间 | 演示数量 | 场景任务 | 动作技能 | 采集方式 |
|---|---|---|---|---|---|---|
| AgiBot World | 智元机器人等 | 2024.12 | 100+万 | 100+种 | 数百个 | 遥操作双臂机器人和灵巧手 |
| Open X-Embodiment | Google Deepmind等全球21所机构 | 2023.10 | 140万 | 311种 | 527个 | 单臂、双臂、四足等22种形态机器人 |
| DROID | 斯坦福大学等 | 2024.03 | 7.6万 | 564种 | 86个 | 遥操作单臂 |
| RT-1 | Google Deepmind | 2022.12 | 13.5万 | 2种 | 2个 | 遥操作单臂 |
| BridgeData V2 | 加州大学伯克利分校等 | 2023.09 | 6万 | 24种 | 13个 | 遥操作单臂及脚本编程动作 |
| RoboSet | 卡内基梅隆大学等 | 2023.09 | 9.85万 | 38种 | 12个 | 遥操作单机械臂及脚本编程动作 |
| BC-Z | Robotics at Google | 2022.02 | 2.6万 | 1种 | 12个 | 遥操作单机械臂 |
| MIME | 卡内基梅隆大学 | 2018.10 | 8,260 | 1种 | 20个 | 遥操作单机械臂 |
| ARIO | 鹏城实验室等 | 2024.08 | 300万 | 258种 | 345个 | 遥操作主从双臂机器人 |
| RoboMIND | 国地中心等 | 2024.12 | 5.5万 | 279种 | 36个 | 遥操作单臂、双臂、人形机器人和灵巧手 |
| RH20T | 上海交通大学 | 2023.07 | 11万 | 7种 | 140个 | 遥操作单臂 |
1. Agibot World
- 发布方:智元机器人,上海人工智能实验室等
- 发布时间:2024.12
- 项目链接:
- HuggingFace: https://huggingface.co/agibot-world
- Github: https://github.com/OpenDriveLab/agibot-world
- 项目主页:https://agibot-world.com/
- 数据集链接:https://huggingface.co/datasets/agibot-world/AgiBotWorld-Alpha
- 简介:智元机器人携手上海人工智能实验室、国家地方共建人形机器人创新中心以及上海库帕思,正式开源 Agibot World 项目。AgiBot World 是全球首个基于全域真实场景、全能硬件平台、全程质量把控的百万真机数据集。AgiBot World 数据集中涵盖的场景具备多样化和多元化特点,从抓取、放置、推、拉等基础操作,到搅拌、折叠、熨烫等复杂动作,几乎涵盖了人类日常生活所需的绝大多数场景。
- 规模:包含来自100个机器人的100多万条演示轨迹。在长程数据规模上已超过谷歌 OpenX-Embodiment 数据集十倍。相比 Google 开源的 Open X-Embodiment 数据集,AgiBot World 长程数据规模高出10倍,场景范围覆盖面扩大100倍,数据质量从实验室级上升到工业级标准。

AgiBot World
- 场景:AgiBot World 数据集诞生于智元自建的大规模数据采集工厂与应用实验基地,空间总面积超过4000平方米,包含3000多种真实物品,一方面为机器人大规模数据训练提供场地,另一方面真实复刻了家居、餐饮、工业、商超和办公五大核心场景,全面覆盖了机器人在生产、生活中的典型应用需求。

多样化任务演示
- 技能:AgiBot World 数据集涵盖了家居(40%)、餐饮(20%)、工业(20%)、办公室(10%)、超市(10%)等上百种通用场景和3000多个操作对象。相较于国外广泛使用的 Open X-Embodiedment 数据集和 DROID 数据集,AgiBot World 数据集在数据时长分布上显著提升,其中80%的任务均为长程任务,任务时长集中在60s-150s之间,并且包含多个原子技能,长程数据是 DROID 和 OpenX-Embodiment 的10倍以上,3000多种物品基本涵盖了这五大场景。

Agibot World数据集分布
- 数据采集:AgiBot World 基于全身可控的移动式双臂机器人进行数据采集,配备了视觉触觉传感器、六维力传感器、六自由度灵巧手等先进设备,可用于模仿学习、多智能体协作等前沿研究。智元 Genie-1 机器人包括8个环绕式布局的摄像头,实时360度全方位感知;6自由度灵巧手,末端六维力传感器和高精度触觉传感器;全身拥有32个主动自由度。
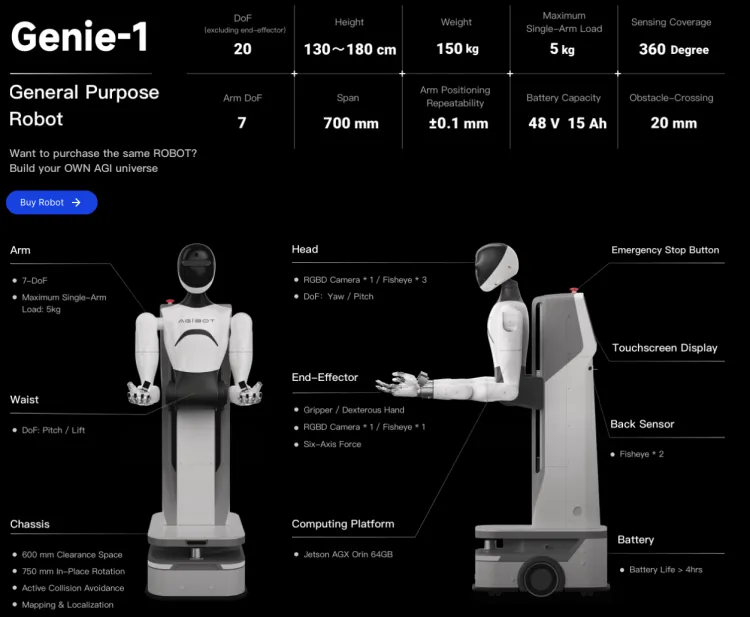
智元机器人
2. Open X-Embodiment
- 发布方:Google DeepMind等全球21家机构
- 发布时间:2023.10
- 项目链接:https://robotics-transformer-x.github.io/
- 论文链接:https://arxiv.org/abs/2310.08864
- 数据集链接:https://github.com/google-deepmind/open_x_embodiment
- 简介:Open X-Embodiment 是由谷歌 DeepMind 联手21家国际知名机构的34个研究实验室,整合60个现有的机器人数据集创建的一个开放的、大规模的标准化机器人学习数据集。Open X-Embodiment Dataset 研究人员将不同来源的数据集转换为了统一的数据格式,便于用户下载和使用,每一组数据以一系列 “episode” 呈现,并通过谷歌制定的 RLDS 格式描述,确保了高度的兼容性和易于理解性。
- 规模:涵盖从单臂机器人到双臂机器人,再到四足机器人等22种不同形态的机器人,共包含超过100万条机器人演示轨迹、311个场景、527项技能和160,266项任务。

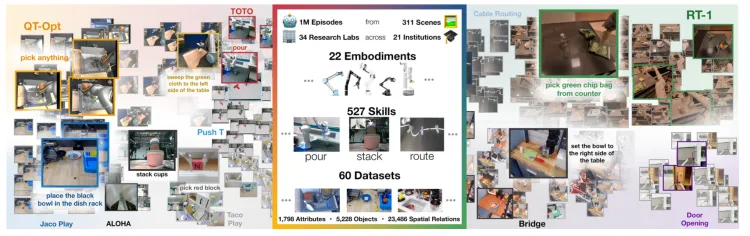
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
- 场景:研究人员在机器人数据混合上训练了两个模型:(1)RT-1,一种专为机器人控制而设计的基于 Transformer 的高效架构;(2)RT-2,一种大型视觉语言模型,经过共同微调,将机器人动作输出为自然语言标记。两种模型均输出相对于机器人夹持器框架表示的机器人动作。机器人动作是一个7维向量,由x、y、z、滚动、俯仰、偏航和夹持器张开或这些量的速率组成。对于机器人未使用其中某些维度的数据集,在训练期间将相应维度的值设置为零。将使用机器人数据混合训练的 RT-1 模型称为 RT-1-X,并使用机器人数据混合训练的 RT-2 模型 RT-2-X。
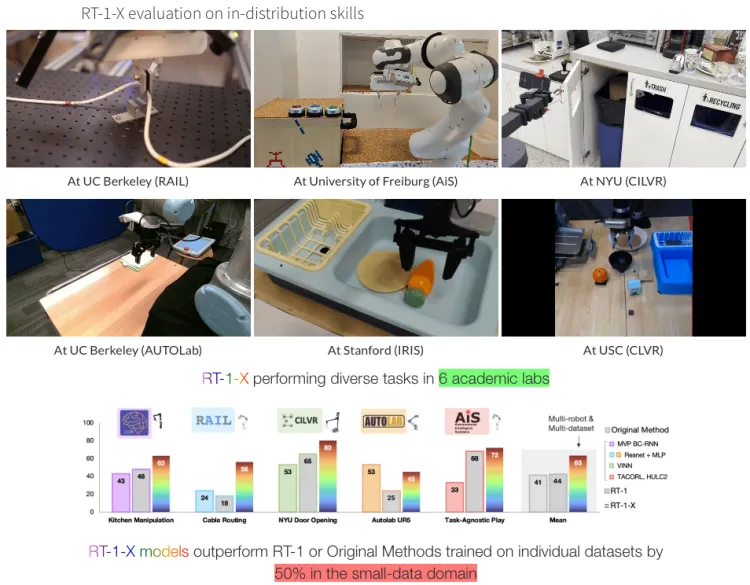
RT-1-X 在小数据领域, 其表现比在单个数据集上训练的 RT-1 或原始方法高出50%
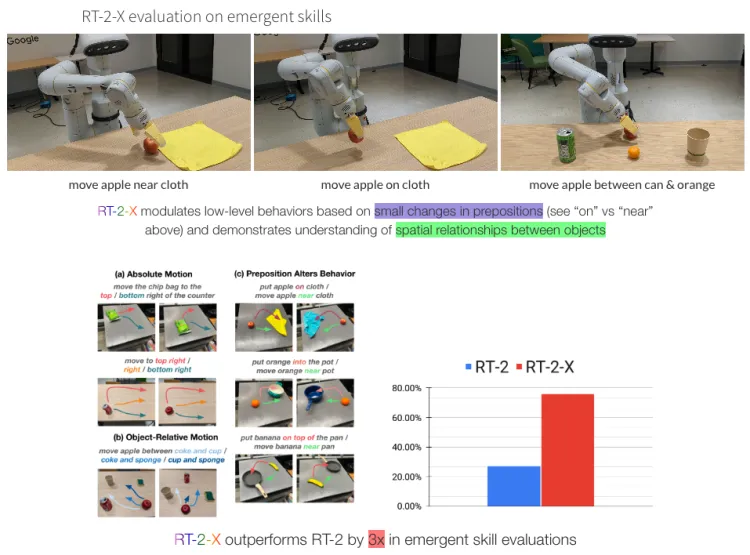
RT-2-X 在新兴技能评估中比 RT-2 高出3倍
- 技能:数据集中常见的任务技能包括picking(捡起)、moving(移动)、pushing(推动)、placing(放置)等,任务目标包括Shapes(外形), Containers(容器), Furniture(家具), Food(食物), Appliances(电器), Utensils(餐具)等。
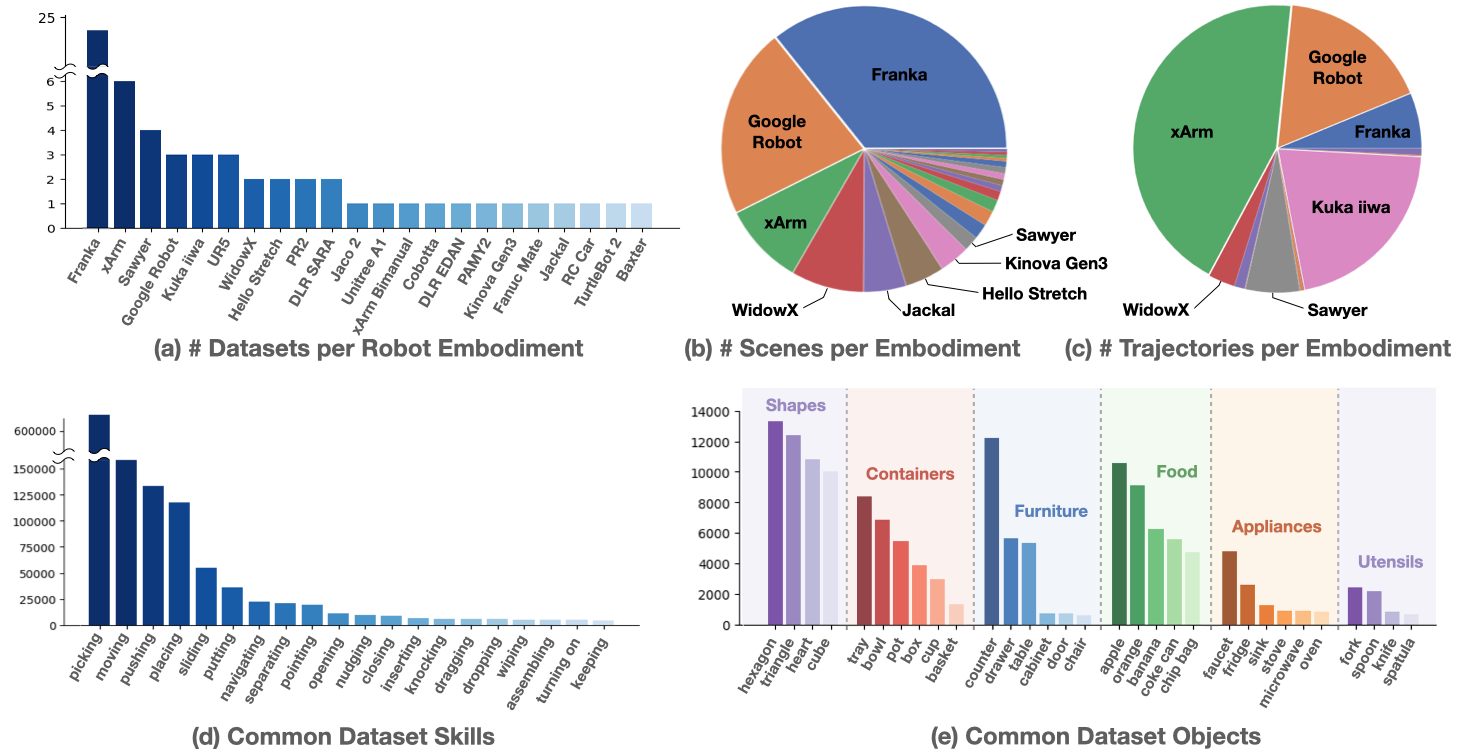
Open X-Embodiment 技能分布
- 数据采集:场景分布上,Franka 机器人占据主导地位,其次是 Google Robot 和 xArm。轨迹分布上,xArm 贡献了最多的轨迹数量,其次是 Google Robot、Franka Kuka、iiwa Sawyer 和 WidowX。

Franka Robotics
3. DROID
- 发布方:Stanford University, UC Berkeley, Toyota Research Institute等
- 发布时间:2024.03
- 项目链接:https://droid-dataset.github.io/
- 论文链接:https://arxiv.org/abs/2403.12945
- 数据集链接:https://droid-dataset.github.io/
- 简介:创建大型、多样化、高质量的机器人操作数据集是迈向更强大、更稳健的机器人操作策略的重要基石。然而,创建这样的数据集具有挑战性:在多样化环境中收集机器人操作数据会带来后勤和安全挑战,并且需要大量硬件和人力投入。研究人员引入了 DROID(分布式机器人交互数据集),这是一个多样化的机器人操作数据集。研究发现与利用现有大规模机器人操作数据集的最先进的方法相比,DROID 将策略性能、稳健性和通用性平均提高了20%。
- 规模:OROID数据集共1.7TB数据,包含76,000个机器人演示轨迹,涵盖86个任务和564个场景。

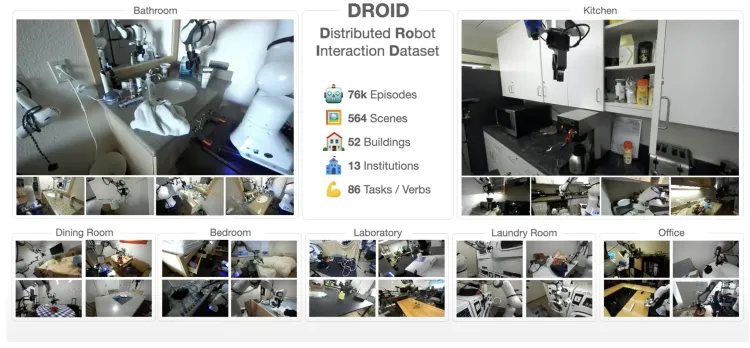
DROID: A Large-Scale In-the-Wild Robot Manipulation Dataset
- 场景:涵盖564个演示场景,包括工业办公室、家庭厨房、工业厨房、办公室、起居室、走廊/壁橱、卧室、餐厅、浴室、洗衣房等场景。

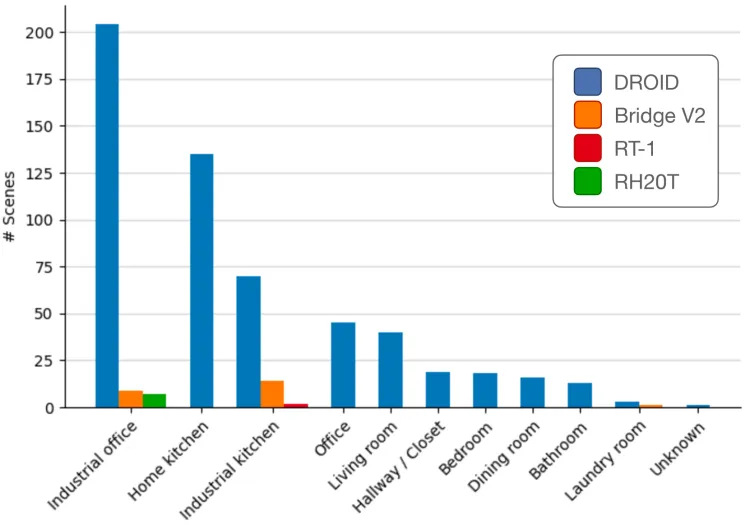
OROID数据集场景分布
- 技能:DROID 数据集包含86种动作任务,涵盖的场景类型范围也更加广泛,且在长尾任务分布中显著多于此前的数据集。
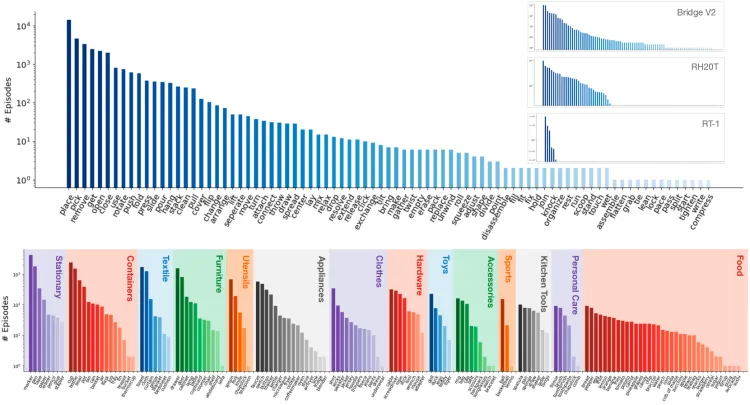
OROID数据集技能分布
- 数据采集:DROID 在所有13家机构中使用相同的硬件设置,以简化数据收集,同时最大限度地提高便携性和灵活性。该设置包括一个 Franka Panda 7DoF 机器人手臂、两个可调节的 Zed 2 立体摄像头、一个腕戴式 Zed Mini 立体摄像头和一个带有用于远程操作的控制器的 Oculus Quest 2 耳机。所有设备都安装在一个便携式、高度可调的桌子上,以便快速切换场景。

DROID数据采集设备
4. RT-2/RT-1
- 发布方:Google DeepMind
- 发布时间:2022.12
- 项目链接:https://robotics-transformer2.github.io/
- 论文链接:https://robotics-transformer2.github.io/assets/rt2.pdf
- 数据集链接:https://github.com/google-research/robotics_transformer
- 简介:2022年,谷歌 DeepMind 研究团队推出了一个大规模的真实世界机器人数据集,以及与之配套的多任务模型 RT-1: Robotics Transformer。2023年7月,研究人员提出 RT-2: Vision-Language-Action Models(VLA,视觉-语言-动作模型)。
- 规模:RT-2 数据集主要来自两大部分,一是约100亿图像-文本对的 WebLI 视觉语言数据集,覆盖109种语言,经筛选后得到10亿个训练样本;二是来自 RT-1 数据集等的机器人数据集,RT-1 通过使用13台配备有7个自由度手臂、两指夹爪和移动底座的EDR机械臂,在17个月的时间跨度内收集了13万个片段,总数据量达到111.06GB,每个片段不仅包含了机器人执行动作的实际记录,还附有对应的人类指令文本标注。

RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
- 场景和技能:RT-2 场景主要集中在家庭、厨房等环境,涉及的物品包括家具、食物、餐具等。涉及的技能主要集中在如 pick-place 等常见操作上,以及 wiping、assembling 等难度更高的技能,捡起和放置物品到更复杂的任务如开关抽屉、处理细长物品、推倒物体、拉扯餐巾纸和开罐子等,涉及超过700种不同物体的任务。

RT-2场景任务
- 研究意义:RT-2 对从未见过的场景性能提升从 RT-1 的32%提升至62%,体现出大规模预训练带来的巨大效益。与在纯视觉任务上进行预训练的基线相比有显著的改进,例如 VC-1 和机器人操作的可重用表示 (R3M),以及使用 VLM 进行对象识别的算法,例如开放世界对象操作 (MOO)。RT-2 表明视觉语言模型 (VLM) 可以转变为强大的视觉语言动作 (VLA) 模型,该模型可以通过将 VLM 预训练与机器人数据相结合来直接控制机器人。

RT-2性能表现对比
5. BridgeData V2
- 发布方:UC Berkeley, Stanford, Google DeepMind, CMU
- 发布时间:2023.09
- 项目链接:https://rail-berkeley.github.io/bridgedata/
- 论文链接:https://arxiv.org/abs/2308.12952
- 数据集链接:https://rail.eecs.berkeley.edu/datasets/bridge_release/data/
- 简介:BridgeData V2 是一个庞大而多样化的机器人操作行为数据集,旨在促进可扩展机器人学习的研究。该数据集与以目标图像或自然语言指令为条件的开放词汇、多任务学习方法兼容。从数据中学习到的技能可以推广到新物体、环境和机构。
- 规模:BridgeData V2 数据集包含60,096条轨迹,其中50,365次是遥控演示,9,731次是通过脚本化的取放策略进行的部署。

BridgeData V2: A Dataset for Robot Learning at Scale
- 场景:BridgeData V2 中的24个环境分为4类。大部分数据来自7个不同的玩具厨房场景,其中包括水槽、炉灶和微波炉的组合。其余环境来自不同的来源,包括各种桌面、独立玩具水槽、玩具洗衣机等。

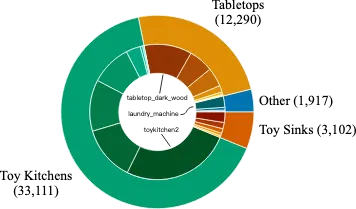
BridgeData V2场景
- 技能:多数数据来自基本的对象操作任务,如拾取和放置、推动和清扫;部分数据来自环境操作,如打开和关闭门和抽屉;还有一些来自更复杂的任务,如堆叠块、折叠布和清扫颗粒介质。

BridgeData V2技能
- 数据采集:数据在 widowx250 6dof 机器人手臂上收集,使用VR控制器远程操作机器人,控制频率为5hz,平均轨迹长度为38个时间步长。采用固定在过肩视图中的 rgbd 相机、两个在数据收集过程中姿势随机的 rgb 相机以及连接到机器人手腕的 rgb 相机进行传感,图像以640x480分辨率保存。
6. RoboSet
- 发布方:Carnegie Mellon University, FAIR-MetaAI
- 发布时间:2023.09
- 项目链接:https://robopen.github.io/
- 论文链接:https://arxiv.org/pdf/2309.01918.pdf
- 数据集链接:https://robopen.github.io/roboset/
- 简介:RoboAgent 项目的 RoboSet 数据集是一个大规模的真实世界多任务数据集,从厨房场景中的一系列日常家庭活动中收集。RoboSet 由动觉演示和远程操作演示组成。该数据集由多任务活动组成,每帧有四个不同的摄像机视图,以及每个演示的场景变化。
- 规模:仅通过7500条轨迹进行训练,就展示了一个通用的 RoboAgent,它可以在38项任务中展示12种操作技能,并且可以将它们推广到数百种不同的未见过的场景。

RoboAgent: Generalization and Efficiency in Robot Manipulation via Semantic Augmentations and Action Chunking
- 场景:主要围绕日常厨房活动场景开展,例如泡茶、烘焙等场景。
- 技能:RoboSet 涵盖了38种任务的12种动作技能。

- 数据采集:使用 Franka-Emika 机器人配备 Robotiq 夹具,通过人类遥操作收集数据,把日常厨房活动分解为不同子任务,在执行这些子任务的过程中记录相应的机器人数据。
7. BC-Z
- 发布方:Robotics at Google、X, The Moonshot Factory、UC Berkeley、Stanford University
- 发布时间:2022.02
- 项目链接:https://sites.google.com/view/bc-z/
- 论文链接:https://arxiv.org/abs/2202.02005
- 数据集链接:https://www.kaggle.com/datasets/google/bc-z-robot
- 简介:研究人员研究了如何使基于视觉的机器人操作系统推广到新任务,从模仿学习的角度来应对这一挑战。为此开发了一个交互式的灵活模仿学习系统,该系统可以从演示和干预中学习,并可以根据传达任务的不同形式的信息进行调节,包括预先训练的自然语言嵌入或人类执行任务的视频。当将真实机器人上的数据收集扩展到100多个不同的任务时,研究人员发现该系统可以执行24个未见过的操作任务,平均成功率为44%,而无需任何机器人演示这些任务。
- 规模:包含25,877个不同的操作任务,涵盖100种多样化的任务。

BC-Z: Zero-Shot Task Generalization with Robotic Imitation Learning
- 场景:
- 物体位置的变化;
- 由于在多个地点收集而导致场景背景的变化;
- 每个机器人之间的硬件存在细微差异;
- 象实例的变化;
- 多个干扰物体;
- 10Hz异步推理下的闭环、仅 RGB 视觉电机控制。这会导致每集做出超过100个决策(即对于稀疏 RL 目标来说具有挑战性的长期任务)。

BC-Z场景任务
8. MIME
- 发布方:The Robotics Institute Carnegie Mellon University
- 发布时间:2018.10
- 论文链接:https://arxiv.org/abs/1810.07121
- 简介:在机器人学习和人工智能领域,让机器人能够通过模仿人类行为来学习复杂的任务是一个重要的研究方向。传统的学习方法在面对复杂的、需要多种交互动作的任务时存在局限性。Multiple Interactions Made Easy (MIME) 项目旨在提供大规模的演示数据,以方便机器人进行模仿学习。通过收集丰富的人类行为演示,使得机器人能够学习到多种交互动作,从而更好地完成复杂任务。MIME 项目通过提供大规模的、包含多种交互动作的演示数据,填补了机器人模仿学习领域在复杂任务数据方面的空白。
- 规模:MIME 数据集中包含超过20个不同机器人任务的8260个人机演示。这些任务的范围从推动物体的简单任务到堆叠家用物品的困难任务,由人类演示的视频和机器人演示的动觉轨迹组成。

Multiple Interactions Made Easy (MIME): Large Scale Demonstrations Data for Imitation
- 技能:MIME 开创性地描述收集演示数据集的方法。MIME 项目包含大量的演示数据,这些数据可以为机器人学习提供充足的样本。丰富的样本数量有助于机器人学习到各种不同的情况和动作模式,从而增强其泛化能力,能够更好地应对真实场景中复杂多变的任务。数据集不仅仅局限于简单的动作,而是涵盖了多种交互动作。例如,在一个家庭场景中,机器人可以学习到像拿起物品、放置物品、打开抽屉、关上抽屉并且将物品放入抽屉等一系列连贯的动作。这种多样性的交互动作数据能够使机器人理解任务的先后顺序和逻辑关系。

MIME动作技能
- 数据采集:使用处于重力补偿动觉模式的 Baxter 机器人。Baxter 是一款双臂机械手,具有 7DoF 臂,配备两指平行夹具。此外,该机器人还配备了安装在机器人头部的 Kinect 和两个 SoftKinetic DS325 摄像头,每个摄像头安装在机器人的手腕上。头部摄像头就像一个外部摄像头,观察桌子上的任务,而腕部摄像头则充当机器人摄像头的眼睛,随着手臂的移动而移动。

机器人演示中的多个视图
9. ARIO
- 发布方:鹏城实验室、南方科技大学、中山大学等
- 发布时间:2024.08
- 项目链接:https://imaei.github.io/project_pages/ario/
- 论文链接:https://arxiv.org/abs/2408.10899
- 数据集链接:https://openi.pcl.ac.cn/ARIO/ARIO_Dataset
- 简介:ARIO(All Robots In One)具身智能数据开源联盟由鹏城实验室、松灵机器人、中山大学、南方科技大学、香港大学等领先机构联合发起。鹏城实验室具身所首先设计了一套针对具身大数据的格式标准,该标准能记录多种形态的机器人控制参数,并且有结构清晰的数据组织形式,还能兼容不同帧率的传感器并记录对应的时间戳,以满足具身智能大模型对感知和控制时序的精确要求。
- 规模:ARIO 数据集共有258个场景,321,064个任务,和3,033,188个演示轨迹。数据模态涵盖2D图像、3D点云、声音、文本和触觉形式。数据有3大来源,一是通过布置真实环境下的场景和任务进行真人采集;二是基于 MuJoCo、Habitat 等仿真引擎,设计虚拟场景和物体模型,通过仿真引擎驱动机器人模型的方式生成;三是将当前已开源的具身数据集,逐个分析和处理,转换为符合 ARIO 格式标准的数据。

All Robots in One: A New Standard and Unified Dataset for Versatile, General-Purpose Embodied Agents
- 场景和技能:ARIO 的场景涵盖桌面、开放环境、多房间、厨房、家务、走廊等。技能涵盖pick、place、put、move、open、grasp等。

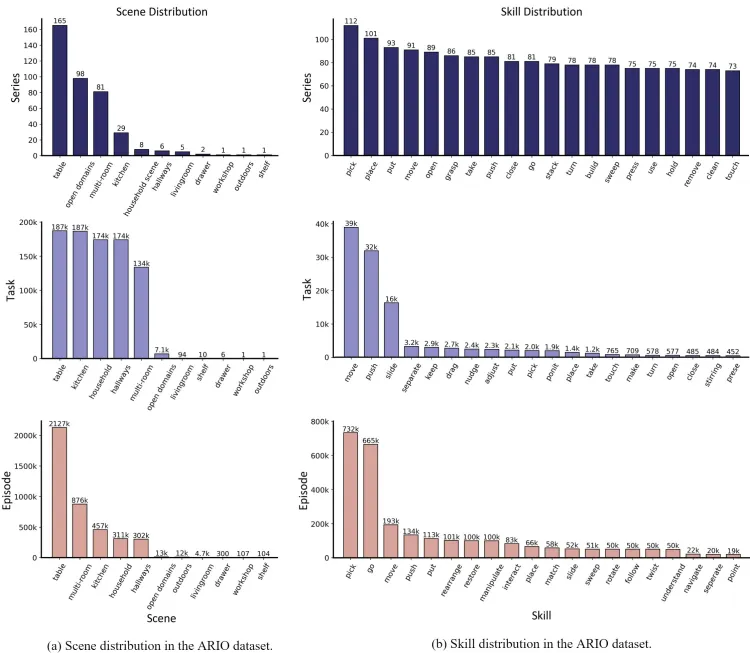
ARIO数据集场景和技能
- 数据采集:基于松灵 Cobot Magic 主从双臂机器人平台,在真实环境下布置场景和任务进行真人采集,设计了30多种任务,包括简单 - 中等 - 困难3个操作难易等级,并通过增加干扰物体、随机改变物体和机器人位置、改变布置环境等方式增加样例的多样性,最终得到3000多条包含3个 rgbd 相机的轨迹数据。

ARIO技能任务
10. RoboMIND
- 发布方:国地共建具身智能机器人创新中心,北京大学,智源研究院等
- 发布时间:2024.12
- 项目链接:https://x-humanoid-robomind.github.io/
- 论文链接:https://arxiv.org/abs/2412.13877
- 数据集链接:https://zitd5je6f7j.feishu.cn/share/base/form/shrcnOF6Ww4BuRWWtxljfs0aQqh
- 简介:RoboMIND 通过人类远程操作收集,包含全面的机器人相关信息,包括多视图RGB-D图像、本体感觉机器人状态信息、末端执行器详细信息和语言任务描述。研究人员不仅发布了55,000次成功运输的轨迹,还记录了5,000次现实世界中的失败案例轨迹。机器人模型可以通过学习这些失败案例轨迹来探索失败的原因,从而通过这种学习经验来提高其性能。这种技术代表了从人类反馈中进行的强化学习(RLHF),其中人类的监督和反馈指导模型的学习过程,使其产生更令人满意和准确的结果。
- 规模:RoboMIND 数据集包含了来自四种不同机器人实体的数据,总计涵盖279项任务中的55,000条轨迹、61个不同的物体类别以及36项操作技能。

RoboMIND: Benchmark on Multi-embodiment Intelligence Normative Data for Robot Manipulation
- 场景:RoboMIND 包含了来自五个使用场景的60多种物体类型,涵盖了大多数日常生活环境:家庭、工业、厨房、办公室和零售。
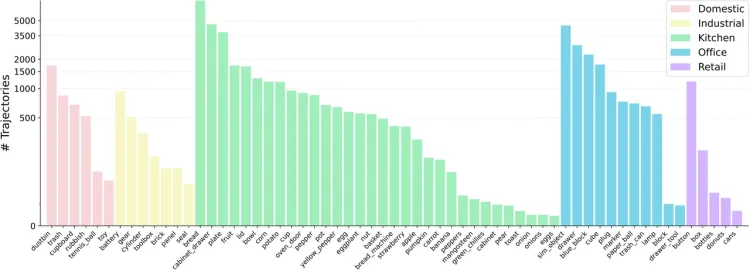
RoboMIND五大场景
- 技能:所有任务被分为六种类型:
- 关节操纵(Artic. M.):涉及打开、关闭、开启或关闭具有关节的物体。
- 协调操纵(Coord. M.):需要机器人双臂之间的协调。
- 基本操纵(Basic M.):包括抓取、握持和放置等基本技能。
- 物体交互(Obj. Int.):涉及与多个物体的交互,例如将一个立方体推过另一个立方体。
- 精密操纵(Precision M.):在物体难以抓取或目标区域有限时必要,如将液体倒入杯子或插入电池。
- 场景理解(Scene U.):与理解场景相关的主要挑战,如从右侧关闭上层抽屉或将四个不同颜色的大块放入相应颜色的盒子中。
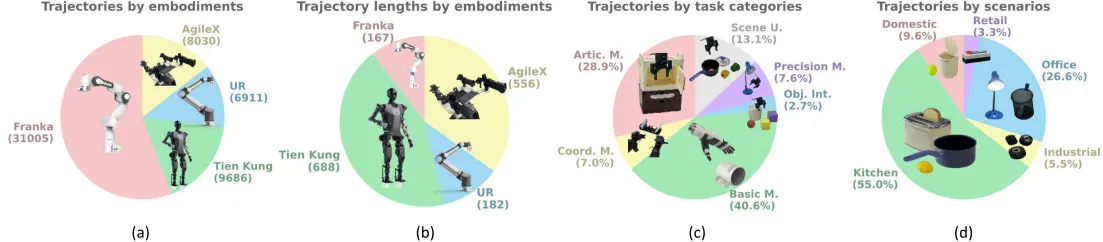
RoboMIND任务分布
- 数据采集:RoboMIND 整合了来自不同机器人类型的数据,包括19,222条来自 Franka Emika Panda 单臂机器人的运动轨迹、9,686条来自 Tien Kung 人形机器人的运动轨迹、8,030条来自 AgileX Cobot Magic V2.0 双臂机器人的运动轨迹、6,911条来自 UR-5e 单臂机器人的运动轨迹,以及11,783条来自模拟的数据。

RoboMIND数据采集
11. RH20T
- 发布方:上海交通大学
- 发布时间:2023.07
- 项目链接:https://rh20t.github.io/
- 论文链接:https://arxiv.org/abs/2307.00595
- 数据集链接:https://rh20t.github.io/#download
- 简介:研究人员致力于释放智能体通过多模态感知泛化数百种真实技能的潜力。为了实现这一目标,RH20T 项目收集了一个数据集,其中包含超过11万个接触丰富的机器人操作序列。这些序列涵盖了来自真实世界的各种技能、情境、机器人以及摄像头视点。数据集中的每个序列都包含视觉、力、音频和动作信息,以及相应的人类演示视频。
- 规模:RH20T 数据集涵盖了多样的技能、环境、机器人和摄像头视点,每个任务都包含数百万个 <人类示范,机器人操作> 对,数据量超过40TB。数据集中的每个序列都包含视觉、力、音频和动作信息,以及相应的人类演示视频。

RH20T: A Comprehensive Robotic Dataset for Learning Diverse Skills in One-Shot
- 技能:研究人员从 RLBench 中选取了48个任务,从 MetaWorld 中选取了29个任务,并引入了70个自提出的、机器人经常遇到且可以实现的任务。

- 数据采集:与以前使用3D鼠标、VR 遥控器或手机简化远程操作界面的方法不同,该项目强调直观、准确的远程操作在收集接触丰富的机器人操作数据方面的重要性。每个平台包含一个带有力矩传感器的机械臂、夹持器和1-2个手持式摄像头、8-10个全局 rgbd 摄像头和2个麦克风用于数据收集。使用触觉设备和踏板,操作员可以直观地远程操作机器人。这些设备都连接到数据收集工作站。

RH20T数据采集
整数智能信息技术(杭州)有限责任公司,起源自浙江大学计算机创新技术研究院,致力于成为AI行业的数据合伙人。整数智能也是中国人工智能产业发展联盟、ASAM协会、浙江省人工智能产业技术联盟成员,其提供的智能数据工程平台(MolarData Platform)与数据集构建服务(ACE Service),满足了智能驾驶、AIGC等数十个人工智能应用场景对于先进的智能标注工具以及高质量数据的需求。

目前公司已合作海内外顶级科技公司与科研机构客户1000余家,拥有知识产权数十项,通过ISO9001、ISO27001等国际认证,也多次参与人工智能领域的标准与白皮书撰写,也受到《CCTV财经频道》《新锐杭商》《浙江卫视》《苏州卫视》等多家新闻媒体报道。

 浙公网安备33010902003900
浙公网安备33010902003900