整数有约 | 决胜AIMO背后的故事:对话NuminaMath-7B主创团队
今年7月,在首届AI数学奥林匹克竞赛中,NuminaMath-7B 从一众数学模型中脱颖而出,以成功解决50道高中难度国际数学奥林匹克竞赛题中的29道的优异成绩,一举成为数学推理领域最顶尖的7B模型。作为 NuminaMath 的合作数据供应商,整数智能有幸邀请到了 NuminaMath 团队的创始人和团队运营负责人,和我们一同分享 NuminaMath-7B 夺冠AIMO背后的故事和团队模型训练的心路历程与经验分享。
嘉宾介绍

李嘉
Numina 的创始人,负责运营 Numina 团队。曾在法国学习,毕业后创立了全球领先的AI远程诊断公司Catalox,利用心电图技术为全球医疗提供创新解决方案。2021年底至2022年初,Catalox被飞利浦收购后,李嘉投身开源项目,并创办了Admin组织。
我们邀请到来自 M-A-P 团队的张舸、昼亮等知名学者与李嘉老师共同探讨Math Model的话题。
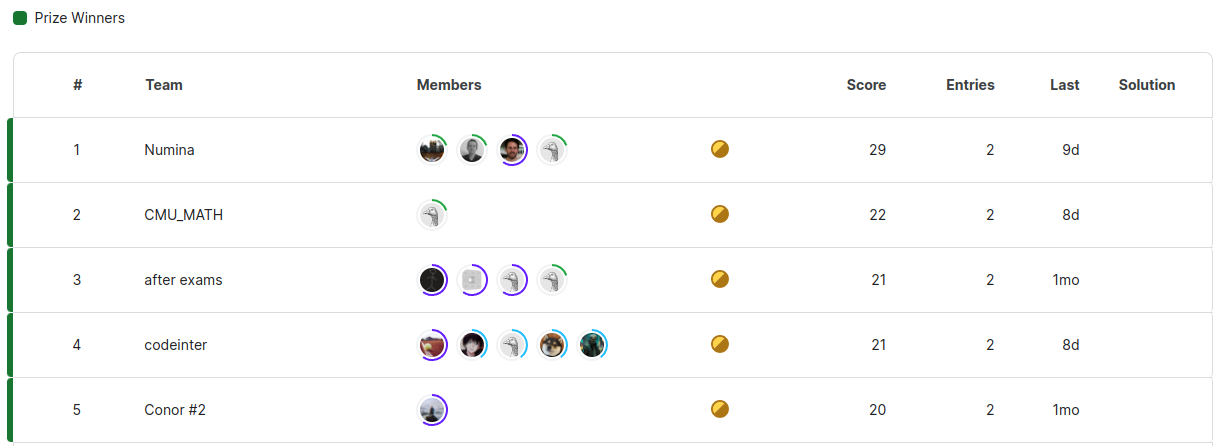
AIMO排行榜中 Numina 排名第一
Q:Numina 涵盖的数学问题和专题包括哪些?使用大量复杂的难题对下游任务帮助大,还是涵盖更广泛的专题对模型的性能提升更有帮助?
A: Numina 包含的数学问题和专题涉及数学竞赛和高考题目。高考题主要提升模型的基础计算能力,尤其是二次函数相关的知识。然而,对于数学竞赛题,高考题的知识点较少用到,因此不收集竞赛题会在竞赛中处于劣势。消融试验表明各类数据源对模型提升都有帮助,但大模型的泛化能力有限,难以覆盖所有知识点。因此,同时收集复杂难题和基础考点来提升模型性能是必要的。应用题方面,当前模型仍需优化和强化。
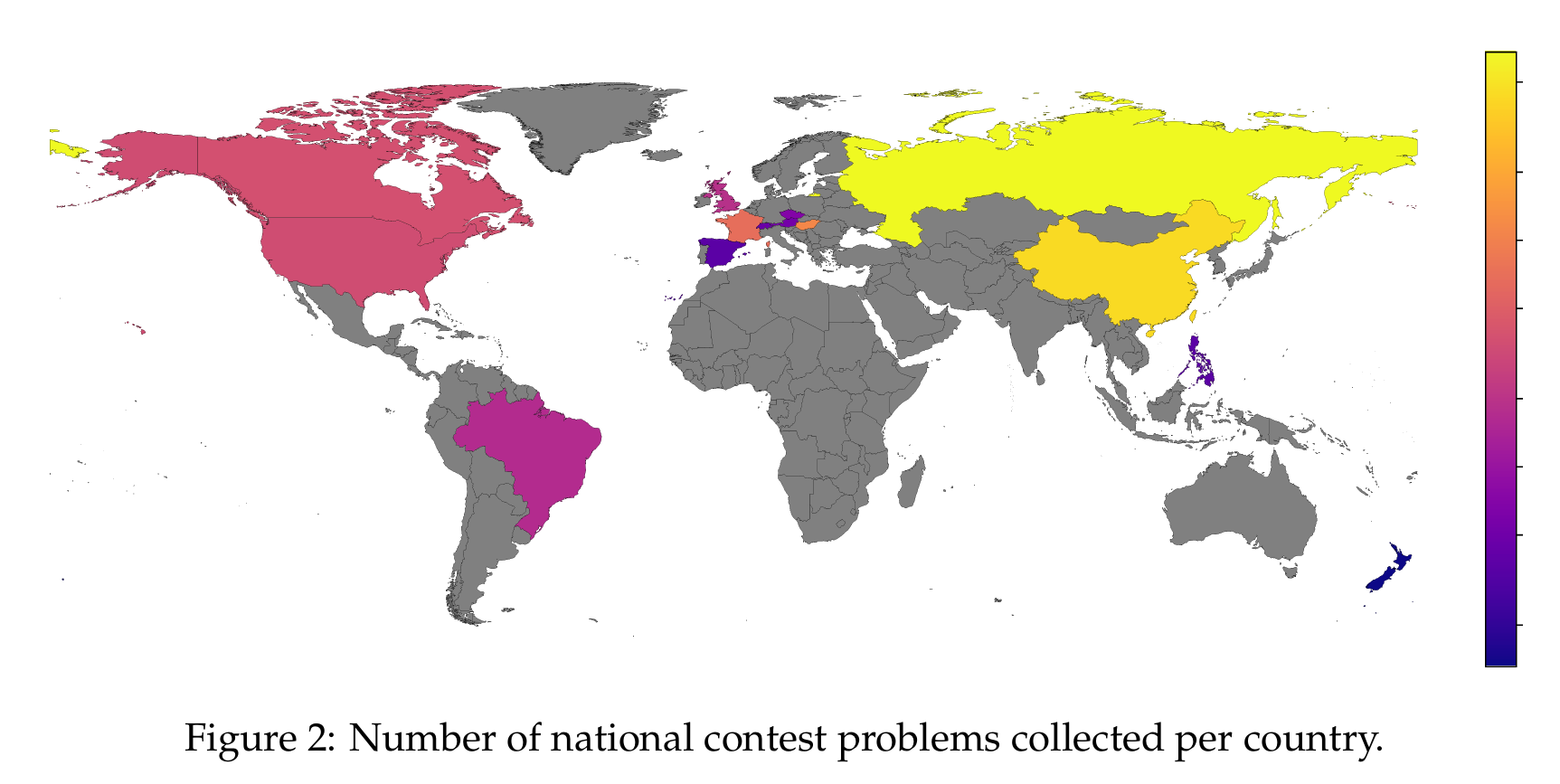
每个国家收集的竞赛题目数量
Q:在你们的实验中如何进行数据的采集,或者说决策数据生产的一些决定?比如采集哪些数据,以及在训练过程中如何对数据进行筛选?
A: 在项目中,数据采集和决策在以下几个方面展开:
- 主要参考现有行业工作的标准,尤其是合成数据。这些合成数据能够在大规模题目上训练模型,提高模型有限的泛化能力,Numina 团队结合经验和工程实践设计了一套Workflow用于数据生成。从分布上看,合成数据在数据集中占据一半左右的比例,并且涵盖不同难度。
- 受 Deepseek Math 工作的启发,收集了大量高质量高考题目数据,有利于模型的微调。
- 为了适应这次以竞赛,特别收集了难度相当的题目,如各国竞赛预选赛、地区选拔赛和国内高中数学联赛的预赛填空题。
- 通过小模型在 Validation Dataset 上的消融试验,验证数据集是否能提升性能,进而决定哪些数据源需要使用或格式化。同时要建立足够鲁棒和有代表性的测试集进行提前验证,以确保模型和数据在目标域内的有效性。
这些决定结合了理论和实践经验,是为提升模型性能而进行的系统性过程。

使用的数据集和数据量
Q:数据合成方面有哪些经验可以分享?
A: 我们当时参考了业界一个比较成熟的方案,文章中直接针对问题做数据增强,然后让GPT来生成类似的题目。我们当时套用了它的方法,但是他们没有开源数据集,所以我们把这个数据集开源出来了。随着更优秀方案的涌现,Numina 团队一直在整理和吸收这些新的研究成果,并结合自身思考,力求开发出更高效的合成题目方法。
Q:如何保证问题Statement以及Diverse的合理性?
A: 使用了 Self-Refine 的方式做纠错,现在还没有一个特别鲁棒的 Verifier 来保证模型输出的结果是百分之百可用的,更多是看平衡以及取舍,这个方案仍然有较大的局限性,Numina 团队在逐步解决这个问题。
Q:合成数据的收益有多大?与用收集的数据多训练几次相比,收益仍旧明显吗?
A: 合成数据带来增益很大的,把之前的数据多训练几遍应该不会带来更多的增益,数据合成相当于达到了一个数据增强的效果,有一些题目它本身不会,数据增强之后就能学会了。譬如我们 Numina 数据集上的合成数据,大概有二三十万条左右,那你用这些数据去训练这个模型,譬如你训练一个 Deepseek Math,它能把模型在数学上的性能从36带到50左右,会带来大概15%的提升,合成数据对它性能提升的影响已经非常大了。
Q:CoT/PRM 是否有看好或有跟进,有没有一些前期的实验结论?
A: Deepseek 给 Numina 团队带来很多启发,这些工作也被证明是非常有效的。因为时间问题没有很大的精力去做这个工作,但仍在探索这一领域的潜力。同时进行一些 KTO 相关研究,这是一种成本较低的方法,通过让模型在已学习的数据集上生成多个答案,再进行偏好对齐,选择正确的输出,相当于一种弱监督的结果奖励模型,对性能提升有帮助。尽管受到比赛时间的限制,我们计划未来分享 PRM 和 KTO 的相关研究成果。
Q:KTO 对性能的帮助能量化吗?
A: 在Math的最高难度(Level 5)上,KTO 方法让模型性能从原来的67-68%提升到约70%,实现了几个百分点的增长。预计在整体Math测试中,使用 KTO 方法可能带来3到5个百分点的性能提升。
Q:是否尝试过使用 Lean 来提高模型能力?如何看待 Python 和 Lean 对 Math Model 的影响?
A: 虽然对 Lean 的尝试受限于其技术不成熟,我们计划在它发展成熟时加以利用。作为一个计算工具,Python 提供了计算能力,可以通过暴力搜索来解决某些数学题目。尽管依然在早期阶段,Lean 未来可能作为验证工具使用,帮助在解题后验证答案或处理相似问题。尽管 Deepseek Prover 有所进展,但实际形式化解题仍存在挑战,而 Alpha Proof 做的比较好,但尚未公开。一旦 Lean 成熟,可以与 Python 形成互补,Python 着重计算,Lean 侧重验证。这种组合有可能显著提高模型在数学问题上的处理能力,通过多样化策略解决更复杂的问题。
Q:同时生成 CoT 和 Python 的过程中,Python 会不会失真,或者没那么好地完成前面 CoT 的内容?
A: 尽管前面明确指定了公式及其应用方式,代码实现中出现错误的概率相对较低,但仍存在一定几率出现幻觉现象。可以通过多次采样的方式来解决这个问题。
Q:基于上面的问题,以 Deepseek Math 作为基模生成正确的Code的成功率是多少?
A: 在没有微调的情况下,Deepseek Math 在 Zero Shot 数学数据集上的成功率为58%,在论文中我们有报告过这个数据。经过模型微调后,成功率可以提高到68%。
Q:你们是否尝试过更大的模型,用不用代码对性能的影响大吗?
A: Qwen 72B 在 Math 上不用代码能达到68%,用代码能达到75%。
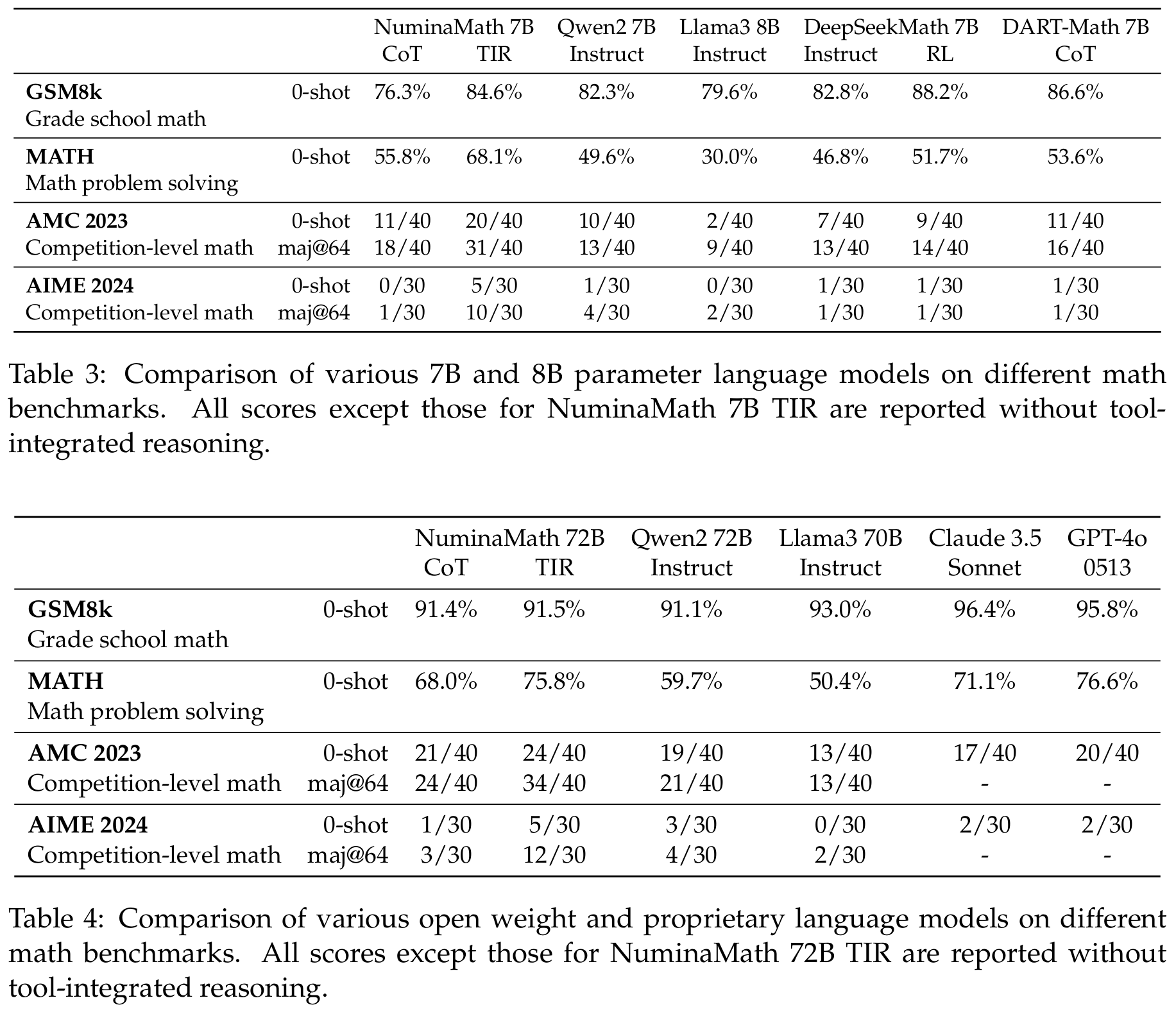
比较不同参数量的模型在各种数学基准上的表现
Q:如何对Response的过程和结果做监督?采样的退出条件是什么?
A: 首先可以通过人工标注提供明确的标签,有助于对模型结果进行监督。使用GPT生成多个答案,然后根据已知正确答案选择正确的输出,用它来训练模型。如果生成的答案错误,则抛弃。通过这种方法,能够较低成本的获取相对高质量的数据并提高模型能力。退出条件就是采样k轮后还是没有正确答案,这种题目我们会直接放弃掉。
Q:证明题如何利用?
A: 在拿AIMO的金牌的项目的时候还没有很好的方案,但是马上会有很重磅的新工作Release出来。
Q:难题都被放弃掉了如何保证diverse?使用GPT生成的数据训练那性能的上限是不是就是GPT?
A: 通过建立验证机制,选择GPT无法直接解决但经过验证机制后可能成功的解法。这增加了生成数据的多样性。在训练过程中,提供部分标准答案或提示,可以显著提高GPT生成正确答案的成功率。通过这种方式,模型可能超越单纯GPT生成的性能上限。尽管初始标注上线为GPT,但在标注过程中进行筛选,去除GPT无法有效处理的数据。同时借鉴了Meta关于 Mask 的一些设计,通过告诉模型更多先验增加生成正确答案的可能性。通过这些方式构造出来的数据效果会好很多。
Q:会有很多PDF的数据被采集吗?如何使用这些数据?
A: 会用到很多PDF上的数据,一般OCR后再用GPT清洗一遍。
Q:您怎么看待 DeepMind 的 Alpha Proof?你觉得AP的性能在本质上比 Numina 好的原因在哪里?
A: Alpha Proof 是与 Alpha Go 同等重要的突破性研究,但是很可惜宣传工作可能没跟上。它展示了在规模足够大的情况下,复杂问题可以被有效解决,这表明了其方法的成熟性和创新性。他们基本上把这个 IMO 的很多后续的研究给就给做完了,他们应该有很多非常先进的理念,Numina 团队也会尝试追赶。
Q:你们之后有计划怎么去迭代 Numina 吗?这方面的未来工作是否有什么insights可以分享?
A: 首先我们主要还是开始打算做形式化,之后会加速推进优质数据的形式化处理,以提高题目求解的准确性和有效性。学习 Alpha Proof 的成功经验,努力在这一领域深化研究。计划将形式化处理的数据开源,帮助学界进行复现相关研究,推动更广泛的认知和实践创新。
Q:关于Proof有没有一些内容值得分享?
A: Proof最大的问题就目前现阶段缺少好的验证的方式,应用Proof的数据的话是对性能有提升的。但是目前没有很好验证手段,直觉上一定是对性能的提升有帮助的。
业务合作
Q:和整数合作的过程中,有没有您觉得做得比较好的地方,或者是说对我们的服务有什么改进或者建议?
A: 我个人是非常感谢整数智能的。整数智能在我们的数据整理过程中提供了很大的帮助。做得好的地方非常多。比如说响应速度非常快,而且整个团队都非常可靠,团队也会和我们一起反复检验。
也很庆幸有整数团队的陪伴,我们有一些前沿的、相对不成熟的想法他们也很愿意去支持,从数据生产的角度给我们一些建议,平衡质量、速度、价格的问题,让团队可以从繁杂的人员管理、数据管理问题中抽离,帮助我们能更专注在科研上。
在规则的打磨上给出的建议也很有建设性,给到的feedback也非常及时,未来更多的探索工作将会和整数一起共建。
整数智能信息技术(杭州)有限责任公司,起源自浙江大学计算机创新技术研究院,致力于成为AI行业的数据合伙人。整数智能也是中国人工智能产业发展联盟、ASAM协会、浙江省人工智能产业技术联盟成员,其提供的智能数据工程平台(MolarData Platform)与数据集构建服务(ACE Service),满足了智能驾驶、AIGC等数十个人工智能应用场景对于先进的智能标注工具以及高质量数据的需求。

目前公司已合作海内外顶级科技公司与科研机构客户1000余家,拥有知识产权数十项,通过ISO9001、ISO27001等国际认证,也多次参与人工智能领域的标准与白皮书撰写,也受到《CCTV财经频道》《新锐杭商》《浙江卫视》《苏州卫视》等多家新闻媒体报道。

 浙公网安备33010902003900
浙公网安备33010902003900